前言
在大部分编程语言中,数组都是从 0 开始编号的,但你是否下意识地想过, 从 1 开始不是更符合人类的思维习惯吗?
数组
数组(Array)是一种线性表结构,它用一组连续的内存空间,来存储一组具有相同数据类型的数据
附上维基百科中数组的定义
这么看来,JavaScript中的数组其实更像Java中的容器,JavaScript中的数组可以存储不同类型的数据,长度也可变。后面提到的数组都只是这种基本的数据结构数组,而不是各种语言中的数据类型数组。
这个定义里有几个关键词,理解了这几个关键词,就能彻底掌握数组这种数据结构。
线性表(Linear List)
顾名思义,线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。其实除了数组,链表、队列、栈等也是线性表结构。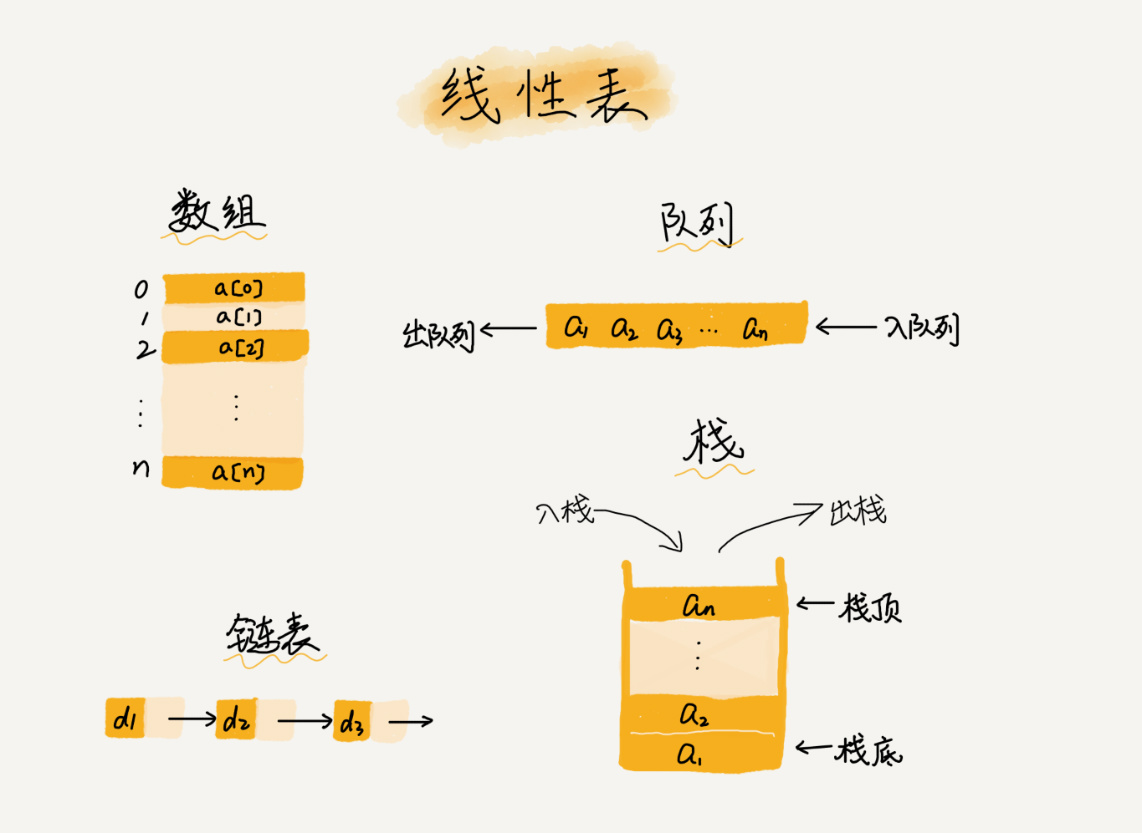
而与它相对立的概念是非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。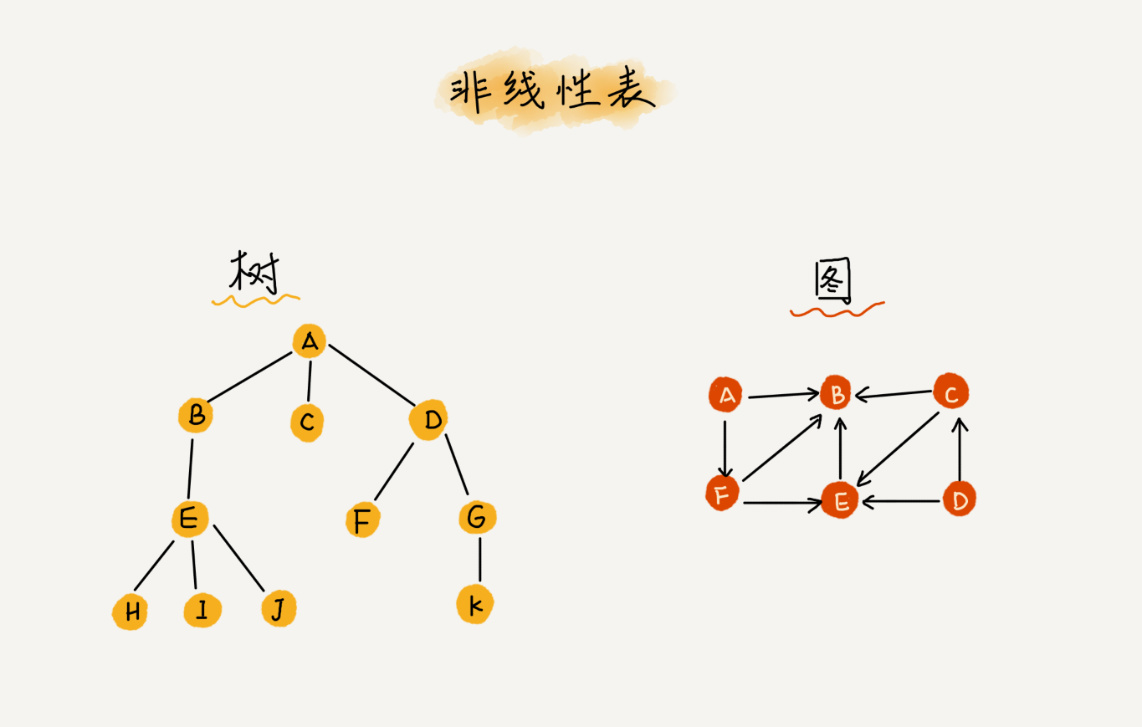
连续的内存空间和相同类型的数据
正是因为这两个限制,它才有了一个堪称“杀手锏”的特性:“随机访问”。但有利就有弊,这两个限制也让数组的很多操作变得非常低效,比如要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据搬移工作。
我们拿一个长度为 10 的 int 类型的数组 int[] a = new int[10] 来举例。在我画的这个图中,计算机给数组 a[10],分配了一块连续内存空间 1000~1039,其中,内存块的首地址为 base_address = 1000。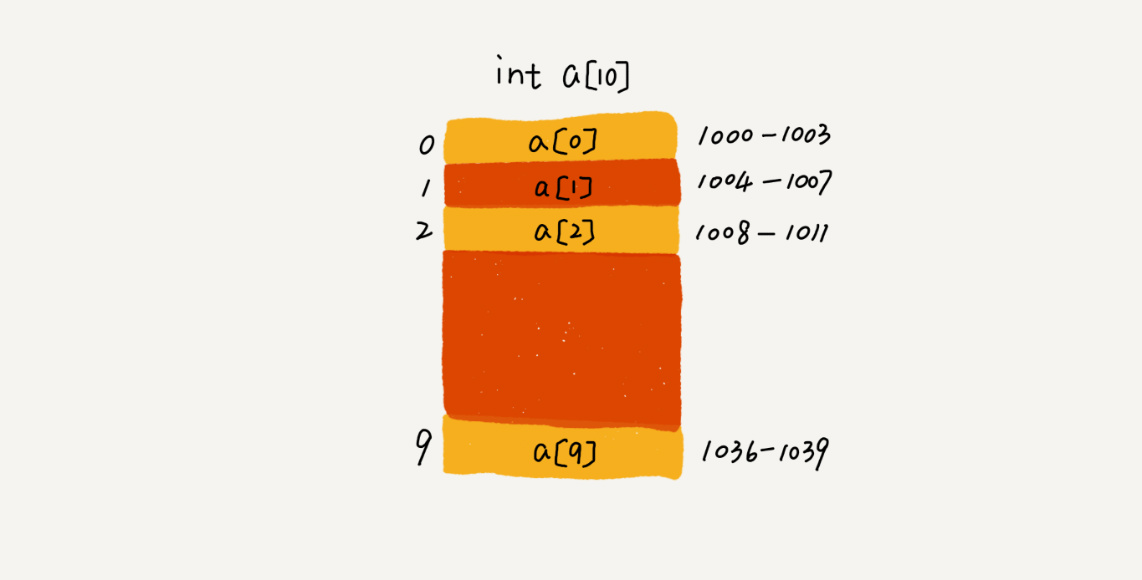
我们知道,计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:a[i]_address = base_address + i * data_type_size
其中 data_type_size 表示数组中每个元素的大小。我们举的这个例子里,数组中存储的是 int 类型数据,所以 data_type_size 就为 4 个字节。
所以数组支持随机访问,根据下标随机访问的时间复杂度是 O(1)
数组的插入和删除
内存数据的连续性让数组能够随机访问。也正是因为需要保持连续性,插入和删除操作就变得复杂。
先看插入操作
假设数组的长度为 n,现在,如果我们需要将一个数据插入到数组中的第 k 个位置。为了把第 k 个位置腾出来,给新来的数据,我们需要将第 k~n 这部分的元素都顺序地往后挪一位。那插入操作的时间复杂度是多少呢
如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为 O(1)。但如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以最坏时间复杂度是 O(n)。 因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为 (1+2+…n)/n=O(n)。
如果数组中的数据是有序的,我们在某个位置插入一个新的元素时,就必须按照刚才的方法搬移 k 之后的数据。但是,如果数组中存储的数据并没有任何规律,数组只是被当作一个存储数据的集合。在这种情况下,如果要将某个数组插入到第 k 个位置,为了避免大规模的数据搬移,我们还有一个简单的办法就是,直接将第 k 位的数据搬移到数组元素的最后,把新的元素直接放入第 k 个位置。
删除操作
和插入类似,如果删除数组末尾的数据,则最好情况时间复杂度为 O(1);如果删除开头的数据,则最坏情况时间复杂度为 O(n);平均情况时间复杂度也为 O(n)。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率就会提高很多。这和垃圾回收机制中的标记清除法的核心思想是一样的。对于要删除的数据我们先不删除而是给它打上要删除的标记,等到所有的数据都检查完毕之后,再触发一次真正的删除操作。
数组下标为何从0开始
查过相关的资料,C语言中最初是如此设计的,后来的出现的各种语言如Java、JavaScript也就效仿了C语言。当然也有很多语言中的数组不是从0开始的,比如Matlab。甚至还有一些语言支持负数下标,如Python。
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 a 来表示数组的首地址,a[0] 就是偏移为 0 的位置,也就是首地址,a[k] 就表示偏移 k 个 type_size 的位置,所以计算 a[k] 的内存地址只需要用这个公式:a[k]_address = base_address + k * type_size
如果下标从 1 开始计数,则a[k]的内存地址公式:a[k]_address = base_address + (k-1)*type_size对于CPU来说多了一次减法指令。
从这个角度看,数组从 0 开始计数有一定的优势。